恰好接触了Kafka,顺便再用Kafka-Stream编写一个基于流式处理的监控程序。
基础概念
- 流处理是一个比较新的概念。与之相对的是批处理,一般认为,批处理可以增加系统的吞吐量,但对于其中单个请求,latency可能会增加。
- 使用流处理是为了得到更低的延迟、更快的反馈,很多信息的价值是随着时间降低的。
流处理
- 流处理非常适合时间序列的数据,检测模式发生改变的数据。
- 如果数据需要被多次传递和访问,就不太适合流处理,比如机器学习算法。
Kafka-Stream
- Kafka是一个消息中间件,具有很高的读写性能。
- Kafka-Stream是一个轻量的java库,可以用流的方式读取和处理Kafka中的消息,并且输出结果到其他地方或写回Kafka。
KStream、KTable
- Kafka-Stream的处理流程可以表示为图,有input、processor、output,其中的input一定是某个topic,processor、output则可以完全自定义。
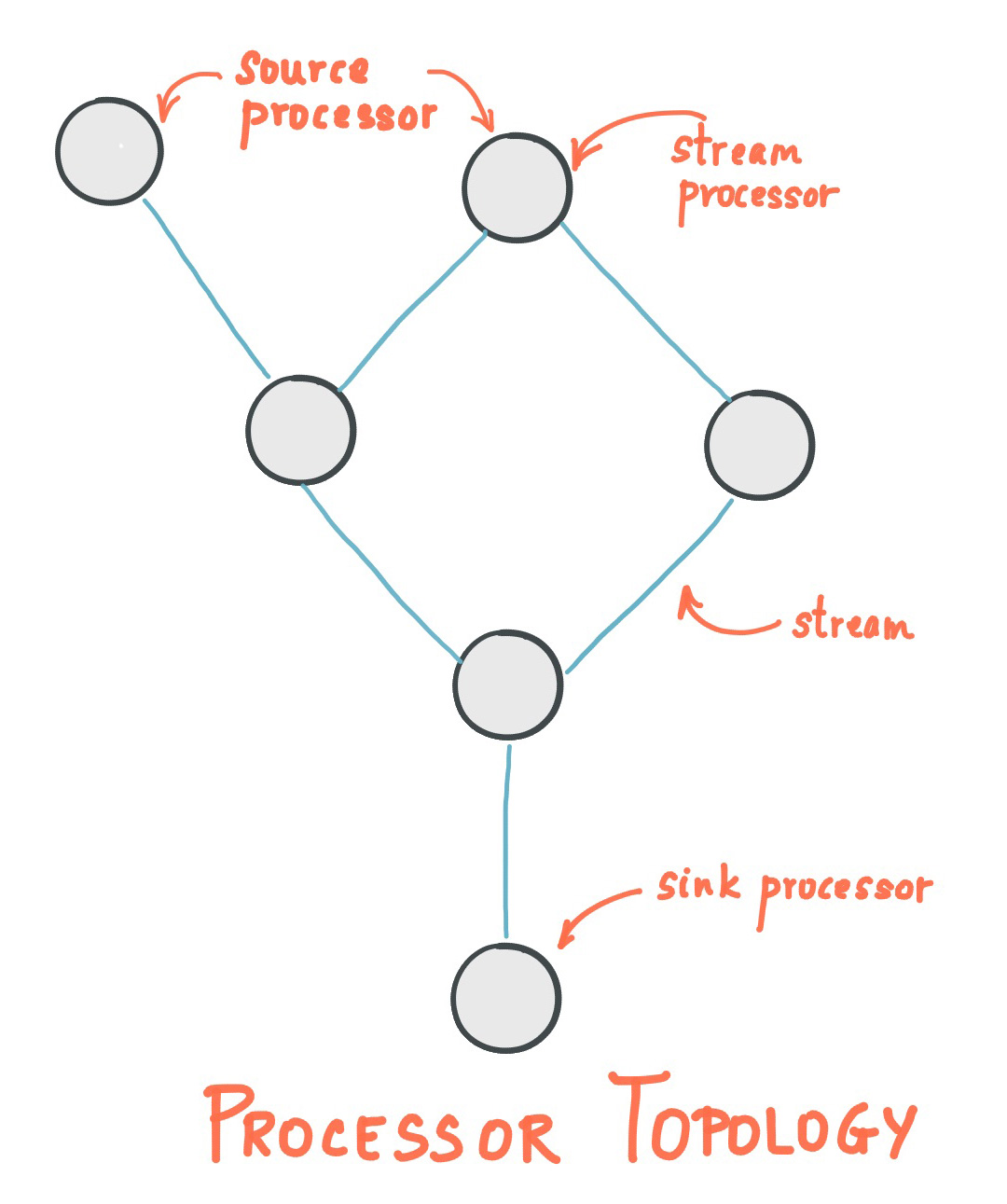
- KStream、KTable则是功能强大的内置processor(从概念上讲如此,但是库的接口设计,看起来有所区别)。
- 需要注意的是,流处理的过程中,总是指明serde类型能避免类型错误。
- KStream的对象具有key-value,常用操作为map。
- KStream经过group就能变成KTable,然后可以使用聚合操作,比如count。
- 当使用count,有一个隐式的memory-state-store被使用,这也是我认为KTable、KStream只是特殊的processor的原因。我们完全可以自己声明processor和store,实现相同的效果。
- TODO:memory-state如何实现并发?
Window
- Window是一类特殊的KTable,它的key是KTable的key在加上时间。
- 时间窗口用于处理实时集合数据。
- 一个非常有意思的问题是,即使是Window,count也不会report 0。KTable无法report 0是很显然的,没有某个消息,那么就没有那个key。我们大多数时候都不清楚有多少个key。
- Window也有相同问题,但是Window的key有两段意义,即消息key+时间key,某些场景下,我们希望能捕捉在某个时间段缺失的数据。
- 遗憾的是,Window是KTable子类,处理方式相同,如果消息key出现过,但是某个时间没有,这个Window仍然不存在。
- Related Problem on stackoverflow
Fault-Tolerant State Store
- state-store默认是会发送change-log给kafka的,从而持久化state。